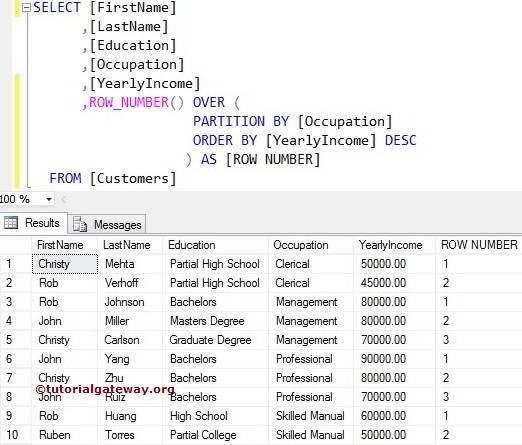
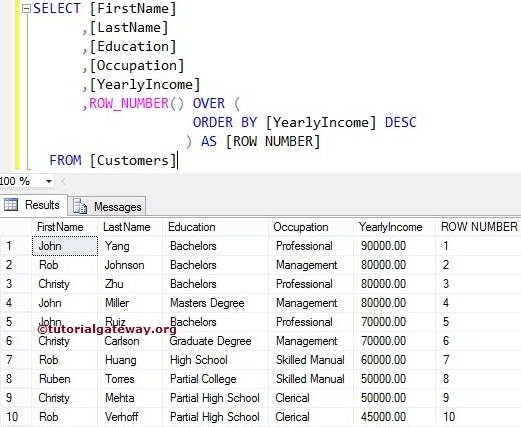
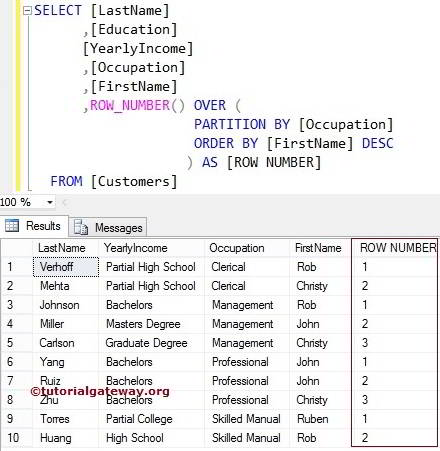
Temporary tables are similar to Permanent tables but Temporary tables are stored in TEMPDB System Database. Temporary tables supports all kinds of operation that one normal table supports. Temporary tables can be created at run time in Stored Procedure. Temporary tables can’t be used in User Defined Function. Temporary tables help the developer to improve performance tuning of query.You can’t use stored procedure SP_Rename to rename the Temporary Table name; it can be used to rename columns of Temporary table. Stored procedures can reference temporary tables that are created during the current session. Within a stored procedure, you cannot create a temporary table, drop it, and then create a new temporary table with the same name.
In SQL Server based on scope and behavior there are two types of temp tables.
1. Local Temp Table
2. Global Temp Table
Local Temp Table: Local temporary table name is stared with single hash ("#") sign. Local Temporary Table scope is Local which means Local temp tables are only available to the current connection for the user; and they are automatically deleted when the user disconnects the connection from instance of SQL Server. If User wants to drop the table then using DROP command it can be deleted.Local temporary tables are visible only to their creators during the same connection to an instance of SQL Server. They cannot therefore be used in views and you cannot associate triggers with them.Constraints and Indexes can be created on Local Temporary table, but we can't create Foreign key reference.
Syntax to create Local Temporary Table
Create Table #Table_Name (Column data_type [Width], ….n)
Let’s create one Local Scope Temporary Table and understands the above explained concept.
CREATE TABLE #LOCALEMPTEMPTABLE (EMPID INT, EMPNAME VARCHAR(100))
(0 row(s) affected)
No more temporary Table Use CTE
Avoid using temporary tables and derived tables as it uses more disks I/O. Instead use CTE (Common Table Expression); its scope is limited to the next statement in SQL query.
The following example shows the components of the CTE structure: expression name, column list, and query. The CTE expression Sales_CTE has three columns (SalesPersonID, SalesOrderID, and OrderDate) and is defined as the total number of sales orders per year for each salesperson.
CTE WITH SINGLE USE
USE ARTEK;
GO
-- DEFINE THE CTE EXPRESSION NAME AND COLUMN LIST.
WITH SALES_CTE (SALESPERSONID, SALESORDERID, SALESYEAR)
AS
-- DEFINE THE CTE QUERY.
(
SELECT SALESPERSONID, SALESORDERID, YEAR(ORDERDATE) AS SALESYEAR
FROM SALES.SALESORDERHEADER
WHERE SALESPERSONID IS NOT NULL
)
-- DEFINE THE OUTER QUERY REFERENCING THE CTE NAME.
SELECT SALESPERSONID, COUNT(SALESORDERID) AS TOTALSALES, SALESYEAR
FROM SALES_CTE
GROUP BY SALESYEAR, SALESPERSONID
ORDER BY SALESPERSONID, SALESYEAR;
GO
CTE WITH MULTIPLE USE
WITH CT (CITYID,STATEID,CITYNAME) AS
(
SELECT CITYID,STATEID,CITYNAME
FROM CITY
),
ST (STATEID,STATENAME, REGIONID) AS
(
SELECT STATEID,STATENAME, REGIONID FROM STATE
),
RT (REGIONID,REGIONNAME) AS
(
SELECT RR.REGIONID,RR.REGIONNAME FROM REGION RR
JOIN ST ON ST.REGIONID = RR.REGIONID
)
SELECT CT.CITYNAME, ST.STATENAME, RT.REGIONNAME
FROM CT
JOIN ST ON CT.STATEID = ST.STATEID
JOIN RT ON RT.REGIONID = RT.REGIONID
IN ABOVE QUERY THE ST CTE IS BEING USED TWICE.
Global Vs Local Temporary Table
Temporary table is a very important part for SQL developer. Here in this article we are focusing about the local and global temporary table.
A global temporary table is visible to any session while in existence. It lasts until all users that are referencing the table disconnect.
The global temporary table is created by putting (##) prefix before the table name.
CREATE TABLE ##sample_Table
(emp_code DECIMAL(10) NOT NULL,
emp_name VARCHAR(50) NOT NULL)
A local temporary table, like #California below, is visible only the local session and child session created by dynamic SQL (sp_executeSQL). It is deleted after the user disconnects.
The local temporary table is created by putting (#) prefix before the table name.
CREATE TABLE #sample_Table
(emp_code DECIMAL(10) NOT NULL,
emp_name VARCHAR(50) NOT NULL)
If we use the block like BEGIN TRANSACTION and COMMIT TRANSACTION/ROLLBACK TRANSACTION the scope of the Local temporary table is within the transaction not out site of transaction.
In SQL Server based on scope and behavior there are two types of temp tables.
1. Local Temp Table
2. Global Temp Table
Local Temp Table: Local temporary table name is stared with single hash ("#") sign. Local Temporary Table scope is Local which means Local temp tables are only available to the current connection for the user; and they are automatically deleted when the user disconnects the connection from instance of SQL Server. If User wants to drop the table then using DROP command it can be deleted.Local temporary tables are visible only to their creators during the same connection to an instance of SQL Server. They cannot therefore be used in views and you cannot associate triggers with them.Constraints and Indexes can be created on Local Temporary table, but we can't create Foreign key reference.
Syntax to create Local Temporary Table
Create Table #Table_Name (Column data_type [Width], ….n)
Let’s create one Local Scope Temporary Table and understands the above explained concept.
CREATE TABLE #LOCALEMPTEMPTABLE (EMPID INT, EMPNAME VARCHAR(100))
The above script will create a temporary local scope table in TEMPDB database. You can find it in Tempdb database using below query
GO
SELECT * FROM TEMPDB.SYS.TABLES
As I have already told, you can perform any operation on Temporary table that a Permanent table supports. Let’s insert few records in recently created temporary table. Insert query will be same to insert data in Temporary tables.
GO
INSERT INTO #LOCALEMPTEMPTABLE VALUES ( 1, 'GHANESH');
Let’s fetch the record from the #LocalEMPTempTable table using below query.
GO
SELECT * FROM #LOCALEMPTEMPTABLE

After execution of all these statements, if you close the query window and again open a new connection and then execute "Insert" or "Select" Command on #LocalEMPTempTable table, it will throw below error.
Msg 208, Level 16, State 0, Line 1
Invalid object name '#LOCALEMPTEMPTABLE'.
This is because the scope of Local Temporary table is only bounded with the current connection of current user. You are using a new connection in which the Local Temporary Table was not created.
Global Temp Table: Global Temporary tables name starts with a double hash ("##"). Scope of Global temporary table is Global which means Once this table has been created by a connection, like a permanent table it is then available to any user by any connection. It will be automatically deleted once all connections have been closed from the instance of SQL Server. User can also drop the table using DROP command. It is suggested to Drop the tables manually using DROP statement if it is not required anymore. Constraints and Indexes can be created on Global Temporary table, but we can't create foreign key references.They cannot be used in views and you cannot associate triggers with them.
Syntax to create Global Temporary Table
Create Table ##Table_Name (Column data_type [Width], ….n)
Let’s create one Global Scope Temporary Table and understands the above explained concept.
GO
CREATE TABLE ##GLOBALEMPTEMPTABLE (EMPID INT, EMPNAME VARCHAR(100))
The above script will create a temporary Global scope table in TEMPDB database. You can find the table in Tempdb database using below query.
GO
SELECT * FROM TEMPDB.SYS.TABLES
As I have already told, you can perform any operation on Temporary table that a Permanent table supports. Let’s insert few records in recently created temporary table. Insert query will be same to insert data in Temporary tables.
GO
INSERT INTO ##GlobalEMPTEMPTABLE VALUES ( 1, 'PRASAD'), ( 2, 'ANSHUL')
Let’s fetch the record from the ##GlobalEMPTempTable table using below query.
GO
SELECT * FROM ##GLOBALEMPTEMPTABLE

After execution of all these statements, if you open a new query window and then execute "Insert" or "Select" Command on ##GLOBALEMPTempTable table, it will execute successfully.
This is because the scope of Global Temporary table is not bound with the current connection of current user. Global temporary tables are visible to all SQL Server connections. When you create one of these, all the users can see it.
In What scenarios Temp Tables should be used?
When a large number of row manipulation is required in stored procedures.
When we are having a complex join operation.
Temporary tables can replace the cursor because we can store the result set data into a temp table, and then we can manipulate the data from there.
Key points to remember about Temp Tables.
Temporary Tables can’t have foreign key constraint.
We can’t create Views on Temporary Tables.
We can’t create Triggers on Temporary Tables.
Temporary Tables will be stored in Tempdb system database.
Temporary Tables are automatically deleted based on their scope.
Temporary Tables can’t be renamed using SP_Rename sytem stored prodecure.
Temporary Tables can’t be used in User Defined Function.
The best way to use a temporary table is to create it and then fill it with data. i.e., instead of using Select into temp table, create temp table 1st and populate with data later.
Temporary Tables can have Indexes, Constraints (except Foreign key constraint).
Temporary Tables Supports Transactions.
Temporary Tables Supports Error Handling.
Temporary Tables Supports DDL, DML commands.
Tables need to be deleted when they are done with their work.
Table Variable:
Alternative of Temporary table is the Table variable which can do all kinds of operations that we can perform in Temp table.
In SQL Server we have a Data Type Table. We can make use of this data type to create temporary tables in database. Table variables are partially stored on disk and partially stored in memory. It's a common misconception that table variables are stored only in memory. Because they are partially stored in memory, the access time for a table variable can be faster than the time it takes to access a temporary table.Table variable is always useful for less data. If the result set returns a large number of records, we need to go for temp table. We don’t use CREATE command to Create Temporary Table Variable, we use DECLARE keyword to create Temporary Table Variable. As I have already mentioned that Table is a data type in SQL Server that is why we use declare keyword just like we use DECLARE keyword for any data type. Functions and variables can be declared to be of type Table.
A table variable behaves like a local variable. It has a well-defined scope. This is the function, stored procedure, or batch that it is declared in.
Within its scope, a table variable can be used like a regular table. It may be applied anywhere a table or table expression is used in SELECT, INSERT, UPDATE, and DELETE statements.
However, table variable cannot be used in the following statement:
SELECT select_list INTO table_variable;
Table variables are automatically cleaned up at the end of the function, stored procedure, or batch in which they are defined.
Here is the syntax for temporary table variable.
DECLARE @TempTableVariable (Column Data_Type Width, … n)
Let’s declare a Table variable and perform Insert and Select operation on it.
GO
DECLARE @EMPTABLEVARIABLE TABLE(EMP INT, EMPNAME VARCHAR(MAX))
INSERT INTO @EMPTABLEVARIABLE VALUES(1,'SUMIT')
SELECT * FROM @EMPTABLEVARIABLE
GO
We can’t run INSERT and SELECT commands separately, we have to include DECLARE Table variable command otherwise it will give below error.
Msg 1087, Level 15, State 2, Line 1
Must declare the table variable "@EMPTABLEVARIABLE".
If you have less than 100 rows generally use a table variable. Otherwise use a temporary table. This is because SQL Server won't create statistics on table variables.
Temporary Table with Dynamic Columns in SP
What the Problem is

When we are working with temporary table on a stored procedure with dynamic columns name we have some problem.
To understand it properly we are just taking an example.
BEGIN
DECLARE @TblCol nVARCHAR(max);
CREATE TABLE #TMPDATE
(date1 DATETIME);
GO
SELECT * FROM TEMPDB.SYS.TABLES
As I have already told, you can perform any operation on Temporary table that a Permanent table supports. Let’s insert few records in recently created temporary table. Insert query will be same to insert data in Temporary tables.
GO
INSERT INTO #LOCALEMPTEMPTABLE VALUES ( 1, 'GHANESH');
Let’s fetch the record from the #LocalEMPTempTable table using below query.
GO
SELECT * FROM #LOCALEMPTEMPTABLE
After execution of all these statements, if you close the query window and again open a new connection and then execute "Insert" or "Select" Command on #LocalEMPTempTable table, it will throw below error.
Msg 208, Level 16, State 0, Line 1
Invalid object name '#LOCALEMPTEMPTABLE'.
This is because the scope of Local Temporary table is only bounded with the current connection of current user. You are using a new connection in which the Local Temporary Table was not created.
Global Temp Table: Global Temporary tables name starts with a double hash ("##"). Scope of Global temporary table is Global which means Once this table has been created by a connection, like a permanent table it is then available to any user by any connection. It will be automatically deleted once all connections have been closed from the instance of SQL Server. User can also drop the table using DROP command. It is suggested to Drop the tables manually using DROP statement if it is not required anymore. Constraints and Indexes can be created on Global Temporary table, but we can't create foreign key references.They cannot be used in views and you cannot associate triggers with them.
Syntax to create Global Temporary Table
Create Table ##Table_Name (Column data_type [Width], ….n)
Let’s create one Global Scope Temporary Table and understands the above explained concept.
GO
CREATE TABLE ##GLOBALEMPTEMPTABLE (EMPID INT, EMPNAME VARCHAR(100))
The above script will create a temporary Global scope table in TEMPDB database. You can find the table in Tempdb database using below query.
GO
SELECT * FROM TEMPDB.SYS.TABLES
As I have already told, you can perform any operation on Temporary table that a Permanent table supports. Let’s insert few records in recently created temporary table. Insert query will be same to insert data in Temporary tables.
GO
INSERT INTO ##GlobalEMPTEMPTABLE VALUES ( 1, 'PRASAD'), ( 2, 'ANSHUL')
Let’s fetch the record from the ##GlobalEMPTempTable table using below query.
GO
SELECT * FROM ##GLOBALEMPTEMPTABLE
After execution of all these statements, if you open a new query window and then execute "Insert" or "Select" Command on ##GLOBALEMPTempTable table, it will execute successfully.
This is because the scope of Global Temporary table is not bound with the current connection of current user. Global temporary tables are visible to all SQL Server connections. When you create one of these, all the users can see it.
In What scenarios Temp Tables should be used?
When a large number of row manipulation is required in stored procedures.
When we are having a complex join operation.
Temporary tables can replace the cursor because we can store the result set data into a temp table, and then we can manipulate the data from there.
Key points to remember about Temp Tables.
Temporary Tables can’t have foreign key constraint.
We can’t create Views on Temporary Tables.
We can’t create Triggers on Temporary Tables.
Temporary Tables will be stored in Tempdb system database.
Temporary Tables are automatically deleted based on their scope.
Temporary Tables can’t be renamed using SP_Rename sytem stored prodecure.
Temporary Tables can’t be used in User Defined Function.
The best way to use a temporary table is to create it and then fill it with data. i.e., instead of using Select into temp table, create temp table 1st and populate with data later.
Temporary Tables can have Indexes, Constraints (except Foreign key constraint).
Temporary Tables Supports Transactions.
Temporary Tables Supports Error Handling.
Temporary Tables Supports DDL, DML commands.
Tables need to be deleted when they are done with their work.
Table Variable:
Alternative of Temporary table is the Table variable which can do all kinds of operations that we can perform in Temp table.
In SQL Server we have a Data Type Table. We can make use of this data type to create temporary tables in database. Table variables are partially stored on disk and partially stored in memory. It's a common misconception that table variables are stored only in memory. Because they are partially stored in memory, the access time for a table variable can be faster than the time it takes to access a temporary table.Table variable is always useful for less data. If the result set returns a large number of records, we need to go for temp table. We don’t use CREATE command to Create Temporary Table Variable, we use DECLARE keyword to create Temporary Table Variable. As I have already mentioned that Table is a data type in SQL Server that is why we use declare keyword just like we use DECLARE keyword for any data type. Functions and variables can be declared to be of type Table.
A table variable behaves like a local variable. It has a well-defined scope. This is the function, stored procedure, or batch that it is declared in.
Within its scope, a table variable can be used like a regular table. It may be applied anywhere a table or table expression is used in SELECT, INSERT, UPDATE, and DELETE statements.
However, table variable cannot be used in the following statement:
SELECT select_list INTO table_variable;
Table variables are automatically cleaned up at the end of the function, stored procedure, or batch in which they are defined.
Here is the syntax for temporary table variable.
DECLARE @TempTableVariable (Column Data_Type Width, … n)
Let’s declare a Table variable and perform Insert and Select operation on it.
GO
DECLARE @EMPTABLEVARIABLE TABLE(EMP INT, EMPNAME VARCHAR(MAX))
INSERT INTO @EMPTABLEVARIABLE VALUES(1,'SUMIT')
SELECT * FROM @EMPTABLEVARIABLE
GO
We can’t run INSERT and SELECT commands separately, we have to include DECLARE Table variable command otherwise it will give below error.
Msg 1087, Level 15, State 2, Line 1
Must declare the table variable "@EMPTABLEVARIABLE".
If you have less than 100 rows generally use a table variable. Otherwise use a temporary table. This is because SQL Server won't create statistics on table variables.
Temporary Table with Dynamic Columns in SP
What the Problem is
When we are working with temporary table on a stored procedure with dynamic columns name we have some problem.
To understand it properly we are just taking an example.
BEGIN
DECLARE @TblCol nVARCHAR(max);
CREATE TABLE #TMPDATE
(date1 DATETIME);
INSERT INTO #TMPDATE
(date1)
VALUES ('2014-01-01'),('2014-01-02'),('2014-01-03'),
('2014-01-04'),('2014-01-05'),('2014-01-06');
(date1)
VALUES ('2014-01-01'),('2014-01-02'),('2014-01-03'),
('2014-01-04'),('2014-01-05'),('2014-01-06');
SELECT @TblCol =
STUFF(( SELECT DISTINCT TOP 100 PERCENT
'] DECIMAL(20,2), [' + t2.date1
FROM (
SELECTCONVERT(VARCHAR(25),date1,105) date1
FROM #TMPDATE
) AS t2
ORDER BY '] DECIMAL(20,2), [' +t2.date1
FOR XML PATH('')
), 1, 2, '') + '] DECIMAL(20,2)'
SET @TblCol = SUBSTRING(@TblCol,LEN('VARCHAR(20,2),')+2, LEN(@TblCol));
SET @TblCol = 'CREATE TABLE #tmp_Example ('+@TblCol +')';
EXEC sp_executesql @TblCol;
-- Here i am trying to Use temp table
SELECT * FROM #tmp_Example;
END
Here in this example temp table named #temp_Example has variable columns depending on the value of temp table #TEMPDATE.
Here the table named #tmp_Example is created successfully but not expose it, so we cannot use this tempt able within the procedure.
Solutions of the Problem
BEGIN
DECLARE @TblCol nVARCHAR(max);
CREATE TABLE #TMPDATE
(date1 DATETIME);
STUFF(( SELECT DISTINCT TOP 100 PERCENT
'] DECIMAL(20,2), [' + t2.date1
FROM (
SELECTCONVERT(VARCHAR(25),date1,105) date1
FROM #TMPDATE
) AS t2
ORDER BY '] DECIMAL(20,2), [' +t2.date1
FOR XML PATH('')
), 1, 2, '') + '] DECIMAL(20,2)'
SET @TblCol = SUBSTRING(@TblCol,LEN('VARCHAR(20,2),')+2, LEN(@TblCol));
SET @TblCol = 'CREATE TABLE #tmp_Example ('+@TblCol +')';
EXEC sp_executesql @TblCol;
-- Here i am trying to Use temp table
SELECT * FROM #tmp_Example;
END
Here in this example temp table named #temp_Example has variable columns depending on the value of temp table #TEMPDATE.
Here the table named #tmp_Example is created successfully but not expose it, so we cannot use this tempt able within the procedure.
Solutions of the Problem
BEGIN
DECLARE @TblCol nVARCHAR(max);
CREATE TABLE #TMPDATE
(date1 DATETIME);
INSERT INTO #TMPDATE
(date1)
VALUES ('2014-01-01'),('2014-01-02'),('2014-01-03'),
('2014-01-04'),('2014-01-05'),('2014-01-06');
(date1)
VALUES ('2014-01-01'),('2014-01-02'),('2014-01-03'),
('2014-01-04'),('2014-01-05'),('2014-01-06');
CREATE TABLE #tmp_Example
(COL DECIMAL);
SELECT @TblCol =
STUFF(( SELECT DISTINCT TOP 100 PERCENT
'] DECIMAL(20,2), [' + t2.date1
FROM (
SELECTCONVERT(VARCHAR(25),date1,105) date1
FROM #TMPDATE
) AS t2
ORDER BY '] DECIMAL(20,2), [' +t2.date1
FOR XML PATH('')
), 1, 2, '') + '] DECIMAL(20,2)'
SET @TblCol = SUBSTRING(@TblCol,LEN('VARCHAR(20,2),')+2, LEN(@TblCol));
SET @TblCol = 'ALTER TABLE #tmp_Example ADD'+@TblCol;
EXEC sp_executesql @TblCol;
ALTER TABLE #tmp_Example DROP COLUMN COL;
-- Here i am trying to Use temp table
SELECT * FROM #tmp_Example;
END
Here we create the temp table named #tmp_Example first and then we just alter it and drop the extra columns used in creation.
Output is
01-01-2014 02-01-2014
---------- ---------- …. n
(COL DECIMAL);
SELECT @TblCol =
STUFF(( SELECT DISTINCT TOP 100 PERCENT
'] DECIMAL(20,2), [' + t2.date1
FROM (
SELECTCONVERT(VARCHAR(25),date1,105) date1
FROM #TMPDATE
) AS t2
ORDER BY '] DECIMAL(20,2), [' +t2.date1
FOR XML PATH('')
), 1, 2, '') + '] DECIMAL(20,2)'
SET @TblCol = SUBSTRING(@TblCol,LEN('VARCHAR(20,2),')+2, LEN(@TblCol));
SET @TblCol = 'ALTER TABLE #tmp_Example ADD'+@TblCol;
EXEC sp_executesql @TblCol;
ALTER TABLE #tmp_Example DROP COLUMN COL;
-- Here i am trying to Use temp table
SELECT * FROM #tmp_Example;
END
Here we create the temp table named #tmp_Example first and then we just alter it and drop the extra columns used in creation.
Output is
01-01-2014 02-01-2014
---------- ---------- …. n
(0 row(s) affected)
No more temporary Table Use CTE
Avoid using temporary tables and derived tables as it uses more disks I/O. Instead use CTE (Common Table Expression); its scope is limited to the next statement in SQL query.
The following example shows the components of the CTE structure: expression name, column list, and query. The CTE expression Sales_CTE has three columns (SalesPersonID, SalesOrderID, and OrderDate) and is defined as the total number of sales orders per year for each salesperson.
CTE WITH SINGLE USE
USE ARTEK;
GO
-- DEFINE THE CTE EXPRESSION NAME AND COLUMN LIST.
WITH SALES_CTE (SALESPERSONID, SALESORDERID, SALESYEAR)
AS
-- DEFINE THE CTE QUERY.
(
SELECT SALESPERSONID, SALESORDERID, YEAR(ORDERDATE) AS SALESYEAR
FROM SALES.SALESORDERHEADER
WHERE SALESPERSONID IS NOT NULL
)
-- DEFINE THE OUTER QUERY REFERENCING THE CTE NAME.
SELECT SALESPERSONID, COUNT(SALESORDERID) AS TOTALSALES, SALESYEAR
FROM SALES_CTE
GROUP BY SALESYEAR, SALESPERSONID
ORDER BY SALESPERSONID, SALESYEAR;
GO
CTE WITH MULTIPLE USE
WITH CT (CITYID,STATEID,CITYNAME) AS
(
SELECT CITYID,STATEID,CITYNAME
FROM CITY
),
ST (STATEID,STATENAME, REGIONID) AS
(
SELECT STATEID,STATENAME, REGIONID FROM STATE
),
RT (REGIONID,REGIONNAME) AS
(
SELECT RR.REGIONID,RR.REGIONNAME FROM REGION RR
JOIN ST ON ST.REGIONID = RR.REGIONID
)
SELECT CT.CITYNAME, ST.STATENAME, RT.REGIONNAME
FROM CT
JOIN ST ON CT.STATEID = ST.STATEID
JOIN RT ON RT.REGIONID = RT.REGIONID
IN ABOVE QUERY THE ST CTE IS BEING USED TWICE.
Global Vs Local Temporary Table
Temporary table is a very important part for SQL developer. Here in this article we are focusing about the local and global temporary table.
A global temporary table is visible to any session while in existence. It lasts until all users that are referencing the table disconnect.
The global temporary table is created by putting (##) prefix before the table name.
CREATE TABLE ##sample_Table
(emp_code DECIMAL(10) NOT NULL,
emp_name VARCHAR(50) NOT NULL)
A local temporary table, like #California below, is visible only the local session and child session created by dynamic SQL (sp_executeSQL). It is deleted after the user disconnects.
The local temporary table is created by putting (#) prefix before the table name.
CREATE TABLE #sample_Table
(emp_code DECIMAL(10) NOT NULL,
emp_name VARCHAR(50) NOT NULL)
If we use the block like BEGIN TRANSACTION and COMMIT TRANSACTION/ROLLBACK TRANSACTION the scope of the Local temporary table is within the transaction not out site of transaction.











.JPG&container=blogger&gadget=a&rewriteMime=image%2F*)
.JPG&container=blogger&gadget=a&rewriteMime=image%2F*)